本来以为txt格式的小说都是过时玩意儿,对于txt格式小说我还停留在读高中那会同学建了个下载txt格式小说的论坛,挺火的,据说当时还卖了5K,对于学生时代的我们来说5K当然是巨款了。直到上班工作,txt小说简直就是我上班的动力啊,摸鱼摸鱼。。但是现在由于各种原因,小说很难下载到txt格式的了,百度了一下,小说名加txt,要不就是不能下乱七八糟广告一大堆,要不就是只有没几章,只能在APP看。
闲着没事的休息日,开始研究起番茄小说的APP,发现他下载的小说章节内容全加密的,玩个屌的,然后无意中看到B站的一个视频。当时我就惊呆了,我他妈的怎么没想到啊!用python爬网页版啊,本着能偷懒是偷懒,三连+关注,然后up主发我一个qq群号,我想在群里应该能找到这个程序,想着下载后自己稍微改一改方便自己。谁知道群主意识高啊,直接打包成exe,源码无望,群里当然也有人问有没有源码,当然是没有。打包好的程序还限制了下载目录,群里还充斥着一股铜臭味,有人问想下载制定目录怎么办,有人就会答曰钱+问题=解决。其实如果光光想要下载番茄小说,直接那个程序就够用了。但是我是什么人?然后想着能不能反编译这破逼程序,毕竟我是为了源码去的,网上下载了解包程序pyinstxtractor,解包出来发现真正的程序他打包成了pyd文件,果然是不向让人知道他源码啊。现在路子窄了。。。
然后乱逛又发现了个地方,这里别人给出了爬取番茄小说的python源码,
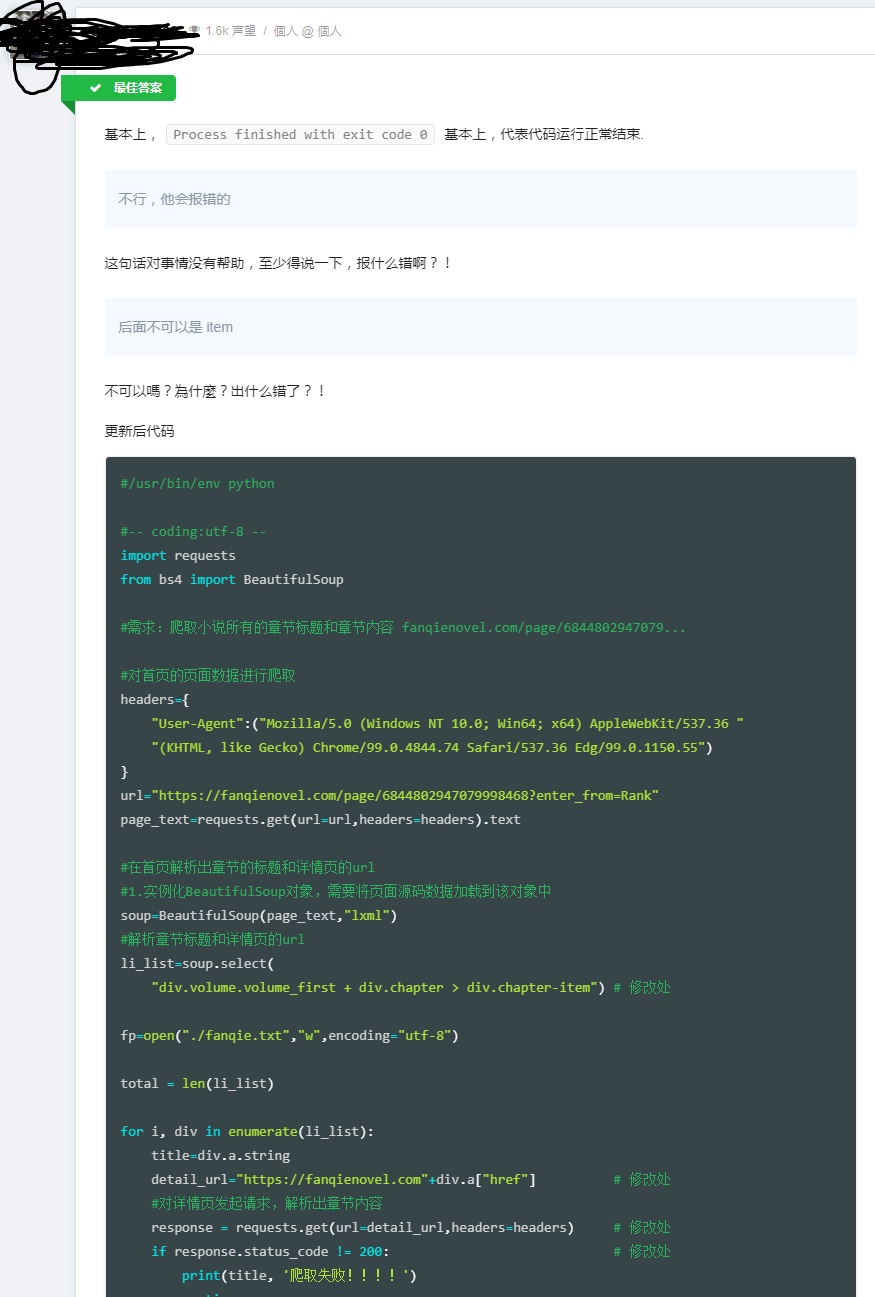
测试了下可以使用,但是爬出来的内容有三个问题
一是部分文字没爬出来。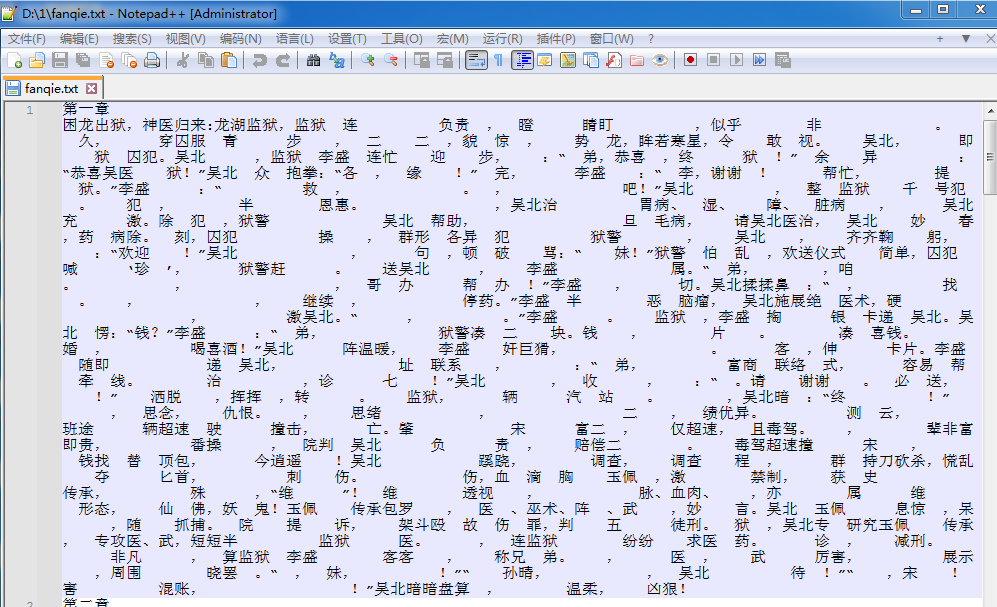
二是没会员账号无法爬全,只能爬几章。(合着我想爬完,还得开个会员?)
三是部分小说章节爬不完。
其实第二个问题好解决,毕竟花钱开会员了事了,在那个群里的时候我就看到那个说明文件说要输入sessionid才可以下到小说全部内容。然后在看视频教学的时候他的sessionid没打马赛克,然后你懂得!
第一个问题本来也觉得挺难的,直到在b站看到了这个视频,视频链接放了,我就大概解释一下好了,其实空白的地方那些字是在的,只是番茄小说吧这些字的unicode编码改了,然后up主又弄了个油猴脚本,这不是又可以拿来用的东西吗?看了一下油猴脚本,简单来说就是把那些被改的字替换回了正常的文字。这就简单了,直接移植到python,改一改代码就行了
第三个问题看了下是部分小说分卷了的只能爬第一卷的内容,翻看源码发现
li_list=soup.select("div.volume.volume_first + div.chapter > div.chapter-item")
看了下把div.volume.volume_first + div.chapter > 删掉即可
最后再源码修改一下,多一个获取书名,然后文件保存为“书名”.txt
效果
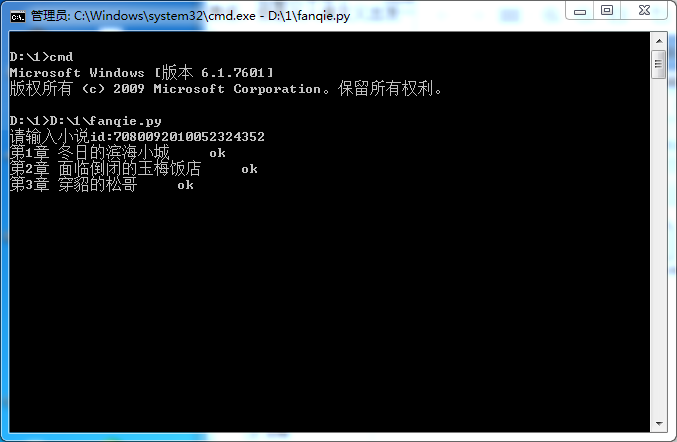
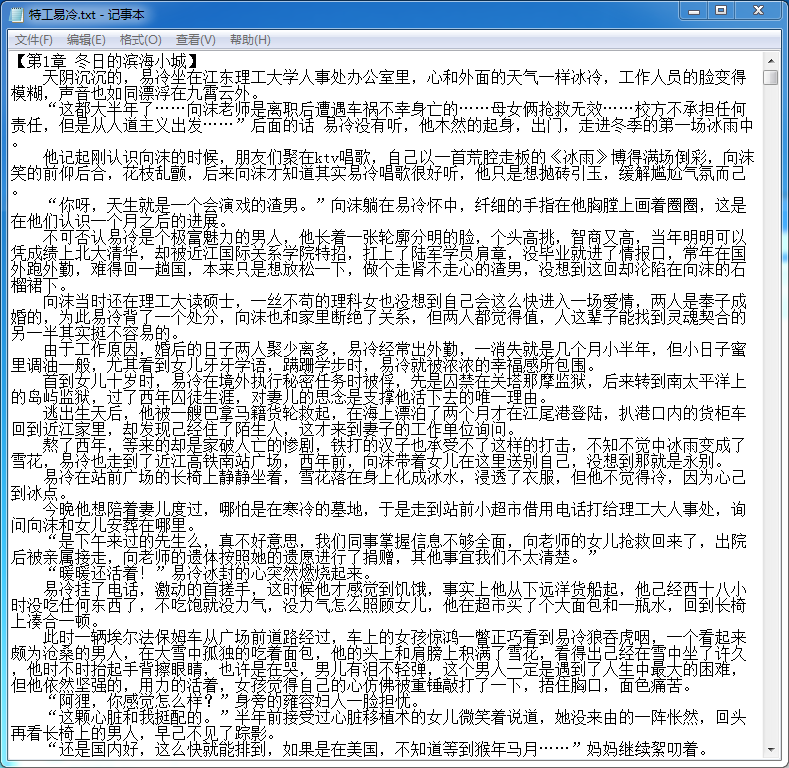
源码不发了,像我一样半吊子的,论坛里那个源码加上油猴脚本就可以写出来,什么都不懂的还是直接b站三连加关注就可以下载到程序,还不用安装python
@wuxiang_xxyi 我自己电脑上找不到了。。网上一大堆,找一个改一下就行了!
源码有吗,可以用其他平台的源码换
@Dlmos火烧云 这玩意要开会员~
能不能给一下sessionid,B站的视频没有了